AI Text to Speech
 Modern scientific illustration of AI Text to Speech
Modern scientific illustration of AI Text to Speech
Mastering Audio Content: The Ultimate Guide to the Best AI Text to Speech Tool (AWS, OpenAI & ElevenLabs)
The internet is no longer just a visual medium. We are in the midst of an audio revolution. From the explosion of podcasts to the necessity of web accessibility, the demand for high-quality audio content has never been higher.
However, content creators and businesses face a persistent bottleneck: Voiceovers are hard.
Hiring professional voice actors is expensive, time-consuming, and difficult to scale. On the flip side, traditional text-to-speech (TTS) engines have historically sounded robotic, jarring, and devoid of emotion.
Enter the next generation of AI Text to Speech. By leveraging the combined power of AWS Polly, OpenAI, and ElevenLabs, our tool bridges the gap between written text and human-like performance.
In this guide, we will explore how this best-in-class AI Text to Speech tool works, why the integration of multiple top-tier engines matters, and how you can leverage it to scale your content production instantly.
What is AI Text to Speech? (A Deep Dive)
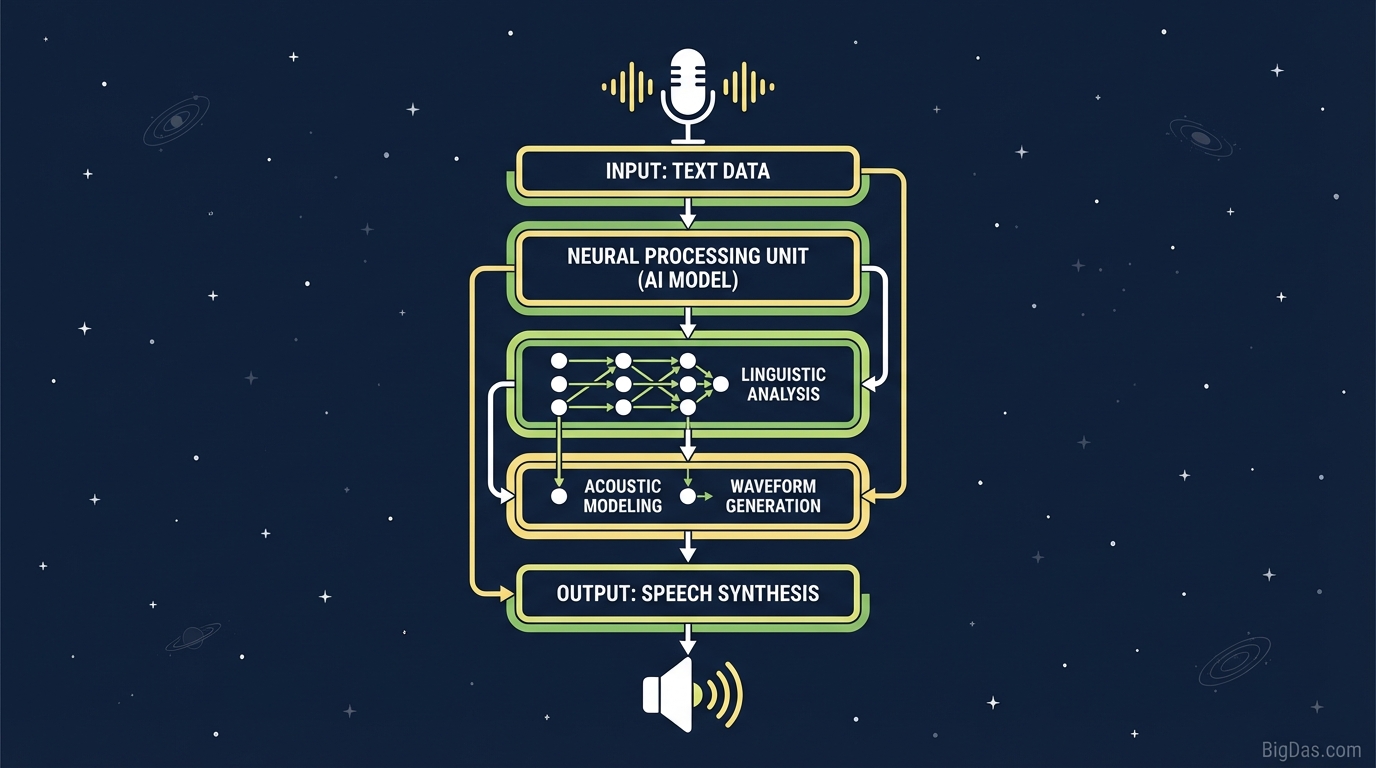
At its core, Text to Speech (TTS) is an assistive technology that reads digital text aloud. However, referring to modern solutions simply as "TTS" is a disservice to the technology. We have moved far beyond the clunky, concatenative synthesis of the early 2000s (think of the old GPS voices).
Modern AI Text to Speech utilizes Neural Text-to-Speech (NTTS). Deep learning and neural networks analyze the context of the text, not just the phonetics. This allows the AI to understand intonation, stress patterns, and breath pauses, resulting in speech that is virtually indistinguishable from a human speaker.
The Power of The "Big Three" Engines
Our tool is unique because it doesn't rely on a single algorithm. It serves as a unified interface for the three most powerful voice synthesis engines in the world:
- AWS Polly (Amazon): Known for its incredible stability and speed. AWS Polly uses advanced deep learning technologies to synthesize speech that sounds like a human newscaster. It is the industry standard for reading long-form articles and accessibility features.
- OpenAI Audio: Bringing the intelligence of GPT models to audio, OpenAI’s voices are renowned for their conversational tone and rich texture. They excel at sounding "helpful" and "engaging" rather than purely informational.
- ElevenLabs: Widely regarded as the current gold standard for emotional realism. ElevenLabs’ generative voice AI captures the nuances of human performance—laughter in the voice, changes in tempo, and dramatic pauses—making it perfect for storytelling and marketing.
By consolidating these technologies, our AI Text to Speech tool offers a versatile palette of voices suitable for any context.
Key Features & Benefits
Why is this specific tool considered best-in-class? It comes down to the synergy of features designed for power users and beginners alike.
1. Multi-Engine Aggregation
Most tools lock you into one provider. We give you the keys to all of them. You can switch between the cost-effective speed of AWS Polly and the hyper-realism of ElevenLabs with a single click. This allows for dynamic content creation where different "characters" can use different underlying engines.
2. Massive Voice Library & Global Reach
With access to these three giants, you unlock:
- Hundreds of Voices: Male, female, and gender-neutral options.
- Multilingual Support: Generate audio in English, Spanish, French, German, Japanese, Hindi, and dozens more.
- Regional Accents: Choose between US, UK, Australian, or Indian English to localize your content perfectly.
3. Granular Audio Control
You aren't just feeding text into a black box. You have control over the output:
- Pitch & Speed: Adjust the speaking rate to fit a specific video timeframe or increase energy by slightly raising the pitch.
- SSML Support: For advanced users, Speech Synthesis Markup Language (SSML) allows you to manually insert pauses, emphasize specific words, or change pronunciation.
4. Commercial Rights & ownership
Unlike hiring a voice actor where you may have to pay royalties for broadcast, the audio generated by our AI Text to Speech tool typically comes with full commercial rights. You own the file, allowing you to monetize your YouTube channel, podcast, or audiobook without legal headaches.
Step-by-Step Guide: How to Use the AI Text to Speech Tool
Ready to turn your script into professional audio? Follow this workflow to ensure the highest quality output.
Step 1: Prepare Your Script
Clean your text. Remove weird formatting, accidental line breaks, or URLs.
- Pro Tip: AI reads what it sees. If you write "St.", it might say "Street" or "Saint" depending on context. For best results, spell out abbreviations if the context is ambiguous.
Step 2: Choose Your Engine (Crucial Step)
This is where you decide the "vibe" of your audio:
- Select AWS Polly if you are converting a 30-page PDF, a technical manual, or need a standard "news anchor" voice.
- Select OpenAI if you are creating a chatbot response, a virtual assistant, or a blog post summary.
- Select ElevenLabs if you are creating a video essay, an audiobook, or an advertisement that requires emotional depth.
Step 3: Select Voice and Language
Browse the dropdown menu. Listen to samples. Do you need a deep, authoritative male voice for a documentary? Or a bright, fast-talking female voice for a TikTok explainer?
Step 4: Input and Customize
Paste your text into the editor box.
- Adjust Speed: If the voice sounds too leisurely for a 60-second Short, bump the speed to 1.1x.
- Add Pauses: Use punctuation strategically. A period (.) creates a full stop. A comma (,) creates a brief pause. An ellipsis (...) often creates a trailing thought.
Step 5: Generate and Download
Click the Generate button. The AI processes the text in the cloud. Within seconds, you can preview the audio. If satisfied, download the high-quality MP3 or WAV file instantly.
Why You Need This Tool: Top Use Cases
The utility of AI Text to Speech extends far beyond simple accessibility. Here is how different industries are leveraging this tool to save thousands of dollars.
1. Faceless YouTube Channels & Social Media
The "Cash Cow" YouTube channel model relies heavily on consistent uploads. Recording voiceovers for 5 videos a week is exhausting. With this tool, you can script, generate, and edit a video in a fraction of the time. The ElevenLabs integration is particularly powerful here, as it retains audience retention better than standard robotic voices.
2. Corporate L&D and E-Learning
Training modules often need updates. If a policy changes, re-hiring a voice actor to record one sentence is a nightmare. With AI, you simply edit the text and regenerate the audio. It ensures consistent voice branding across all your educational materials.
3. Podcasts and Audiobooks
Turning a blog post into a podcast episode allows you to capture users who prefer listening over reading (e.g., during a commute). This increases "Time on Site" and user engagement metrics, which are vital for SEO.
4. IVR and Telephony Systems
"Press 1 for Sales..." usually sounds terrible. Use OpenAI or AWS Polly voices to create professional, welcoming phone menus that improve customer experience and reduce frustration.
5. Accessibility (ADA Compliance)
Making your web content accessible to the visually impaired is not just a moral obligation; in many places, it is a legal requirement. Providing an audio version of your written content ensures you are inclusive of all audiences.
Expert Advice: Getting the Most Out of The Tool
As technical copywriters, we have tested these engines extensively. Here are three secrets to getting a "Human" result:
- The "Lead-in" Trick: If an AI voice sounds too abrupt at the start, type a few "dummy" words at the beginning (e.g., "Okay, let's start. Welcome to..."). Generate the audio, then crop out the dummy words in your editing software. The AI often settles into a more natural rhythm after the first few words.
- Phonetic Spelling: If the AI mispronounces a brand name (e.g., "Adidas" or "Porsche"), spell it phonetically in the text box (e.g., "Ah-dee-doss" or "Por-sha").
- The Comma Hack: If the AI is rushing through a complex sentence, insert extra commas where a human would naturally take a breath. It forces the engine to slow down and parse the logic of the sentence.
Frequently Asked Questions (FAQ)
1. Can I monetize videos using these voices on YouTube?
Yes. The voices generated via AWS Polly, OpenAI, and ElevenLabs through our tool generally grant you commercial rights to the generated audio files. You can use them for YouTube, ads, and paid courses.
2. What is the difference between Standard and Neural voices?
Standard voices rely on splicing together recorded sounds (concatenative). They sound robotic. Neural voices (which our tool prioritizes) use Machine Learning to generate the entire waveform from scratch, resulting in smooth, human-like speech.
3. How many languages are supported?
By aggregating three major providers, we support over 50+ languages and varying dialects, including Spanish (Mexican vs. Castilian), French (Canadian vs. Parisian), and Portuguese (Brazilian vs. European).
4. Is there a character limit?
While individual generations may have limits based on the provider (to ensure processing speed), you can typically generate unlimited audio by breaking your text into chunks.
Conclusion
The era of robotic, disjointed computer voices is over. With the fusion of AWS Polly’s reliability, OpenAI’s intelligence, and ElevenLabs’ emotion, you now have a full production studio at your fingertips.
Whether you are a content creator looking to scale, a business aiming to improve accessibility, or an educator modernizing your curriculum, this AI Text to Speech tool is the ultimate solution. It is cost-effective, incredibly fast, and indistinguishable from reality.
Stop wasting time recording bad audio. Start creating professional voiceovers today.
[> Try the AI Text to Speech Tool Now]